The Future of Data Labeling: Embracing Agents for Efficient and Reliable AI
Adala aims to redefine data processing and model training by combining the computational power of AI with human judgment.

Image Source: pexels
1. The Role of Agents in Data Labeling and AI
Generative AI, exemplified by Large Language Models (LLMs) like ChatGPT, has evolved to become an active collaborator in our day-to-day work. These powerful models can generate human-like text and provide valuable insights across various domains. However, despite their capabilities, LLM-based systems still require human insight, especially for domain-specific or complex tasks, to ensure the quality and reliability of AI models.
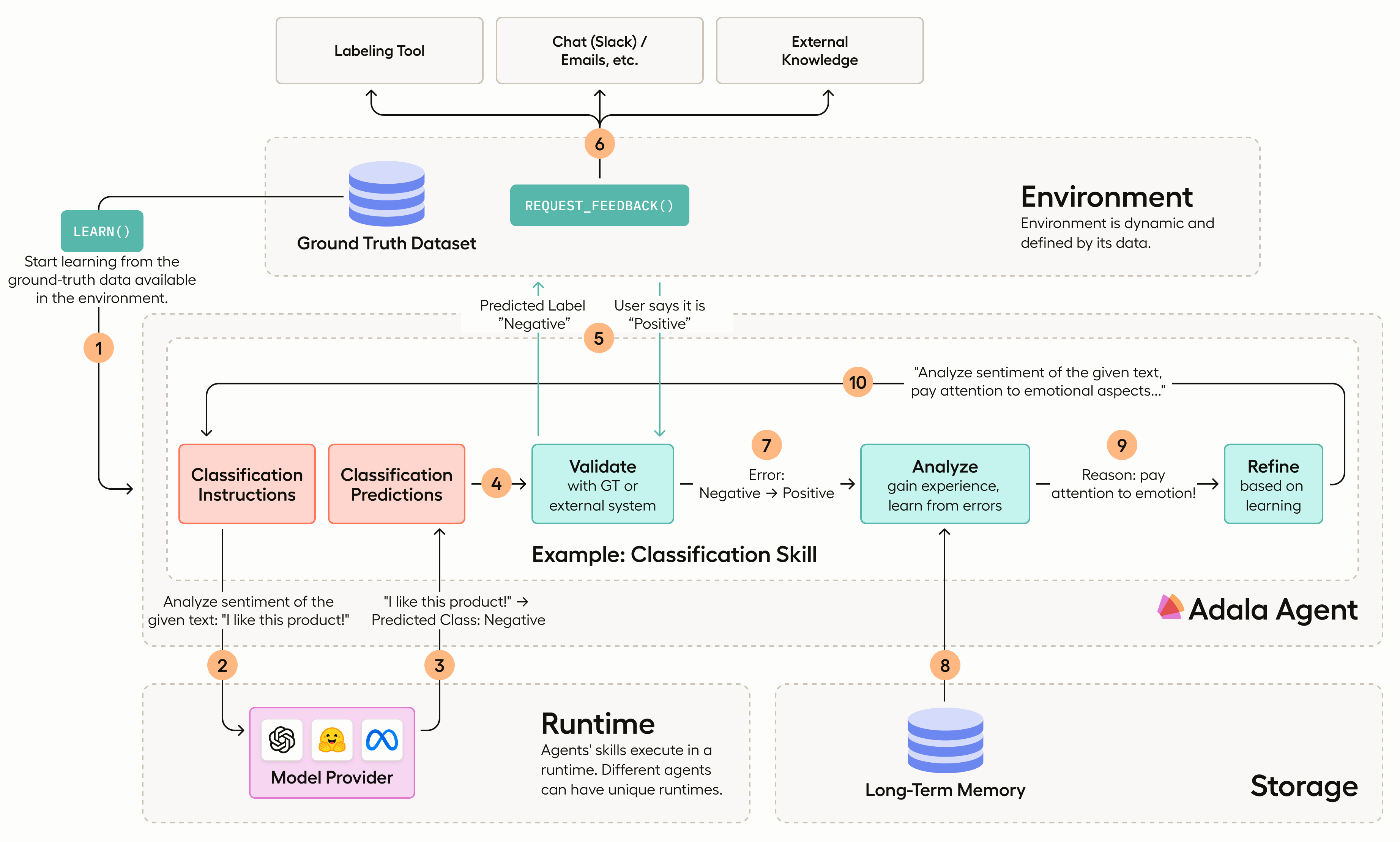
This is where Adala, an Autonomous Data Labeling Agent framework, comes into play. Adala aims to redefine data processing and model training by combining the computational power of AI with human judgment. By leveraging the strengths of both humans and machines, Adala's agents can efficiently label large datasets while maintaining high accuracy.
With Adala's agents, data labeling becomes a collaborative effort between humans and AI. The agents are designed to learn, adapt, and evolve with every interaction, feedback, and new dataset. They possess dynamic capabilities that allow them to adapt to various tasks and deliver accurate results regardless of the nature of the data.
In summary, Adala's agents represent a significant step forward in data labeling for AI. By harnessing the power of LLMs and combining it with human expertise, these agents offer a promising solution for efficient and reliable AI model development.
Add Block
2. The Power of Adala's Agents
Adala's agents are dynamic entities designed to learn, adapt, and evolve, refining their skills with every interaction, feedback, and new dataset. These versatile agents can adapt to various tasks, delivering accurate results regardless of the nature of the data.
The dynamic nature of Adala's agents allows them to improve their performance continuously. With each interaction and feedback received, these agents refine their understanding and decision-making abilities. They can learn from previous labeling tasks and apply that knowledge to future datasets. This iterative process enables the agents to become more accurate and efficient over time.
Efficiency is a key advantage offered by Adala's agents in the data labeling process. Regardless of the complexity or nuance of the data, these agents ensure that the labeling process remains efficient. Powered by Large Language Models (LLMs), Adala's agents can label text datasets at the same or even better quality than skilled human annotators. However, they do so at a significantly faster pace and lower cost.
By leveraging LLMs' computational power, Adala's agents can process large volumes of data quickly while maintaining high accuracy. This efficiency is particularly valuable when dealing with massive datasets that would be time-consuming for human annotators to label manually. The use of Adala's agents not only saves time but also reduces costs associated with manual annotation efforts.
For example, Adala's agents can perform subjectivity detection by classifying product reviews as either "Subjective" or "Objective" statements. This task requires analyzing language patterns and understanding context—a task well-suited for LLM-powered agents. By automating such processes, Adala's agents streamline data labeling workflows and enable organizations to make faster decisions based on labeled data.
3. Enhancing Data Labeling with LLMs
LLMs, such as GPT-4, have the potential to revolutionize AI by enhancing human expertise with AI efficiencies. These powerful language models can be leveraged in data labeling processes to improve efficiency and reduce cognitive burden. By using LLMs as initial label predictors, the labeling process can be expedited, allowing human annotators to focus on more complex or nuanced tasks.
The use of LLMs as initial label predictors speeds up the labeling process significantly. State-of-the-art LLMs can label text datasets at the same or even better quality compared to skilled human annotators but at a much faster pace and lower cost. This not only saves time but also reduces the resources required for manual annotation efforts.
To further improve the reliability and quality of LLM predictions, techniques like chain-of-thoughts prompting can be employed. Chain-of-thoughts prompting involves asking the model to explain its reasoning behind a prediction. By doing so, potential biases or errors in the model's output can be identified and corrected. This approach enhances the transparency of LLM predictions and ensures that they align with human judgment.
Another technique that helps improve label quality is confidence-based thresholding. Confidence-based thresholding involves setting a threshold for accepting LLM predictions based on their confidence scores. This approach effectively mitigates the impact of hallucinations—instances where an LLM generates incorrect or nonsensical labels—and ensures high label quality.
For example, by utilizing Adala's agents, the accuracy of an LLM predictor on a small subset of data was improved from 77% to 92%. This demonstrates how combining human judgment with LLM capabilities can enhance label quality and reliability.
4. The Role of Human-in-the-Loop Curation
Human-in-the-loop curation is crucial in ensuring that AI systems are efficient, context-aware, and reliable by combining human intelligence with AI capabilities. While LLMs like GPT-4 offer impressive performance, human annotators are essential for achieving the highest quality labels, particularly for complex or nuanced tasks.
The involvement of human annotators ensures that AI systems are contextually accurate and aligned with human understanding. Their expertise allows them to handle domain-specific knowledge, interpret subtle nuances in data, and make informed decisions. By incorporating human judgment into the labeling process, organizations can enhance the reliability of their AI models.
When it comes to achieving the best tradeoff between label quality and cost, different options come into play. GPT-4 is the top choice among out-of-the-box LLMs for attaining the highest quality labels. It demonstrates an impressive 88.4% agreement with ground truth compared to 86% for skilled human annotators. This highlights the remarkable capabilities of GPT-4 in generating accurate labels.
However, there are situations where striking a balance between label quality and cost is crucial. In such cases, options like GPT-3.5-turbo, PaLM-2, and open-source models like FLAN-T5-XXL offer compelling alternatives. These models provide a good compromise between label quality and cost-effectiveness.
By considering the specific requirements of a project or task, organizations can make informed decisions about which approach to adopt—leveraging state-of-the-art LLMs like GPT-4 for utmost label quality or opting for more cost-effective alternatives that still deliver satisfactory results.
In summary, human-in-the-loop curation is vital for ensuring efficient and reliable AI systems. Human annotators bring valuable expertise to complex tasks while balancing label quality and cost requires careful consideration of available options. By combining human intelligence with AI capabilities, organizations can achieve high-quality labeled data that forms the foundation of accurate and robust AI models.
5. Agents: Collaborators in Problem-Solving
Agents powered by LLMs, redefine how we interact with technology by making AI a collaborator and partner in problem-solving. These dynamic entities can solve problems in unknown environments, fetching real-time data and providing reliable answers.
One of the key strengths of agents is their dynamic problem-solving abilities. Equipped with LLMs, agents can comprehend complex requests and act on the information using various tools and APIs. They can adapt their approach based on the context of the problem at hand. This flexibility allows agents to tackle diverse challenges and provide tailored solutions.
Agents continuously improve their problem-solving process through feedback loops with LLMs. The heart of an agent lies in its LLM component, which enables it to understand complex queries and generate responses. By receiving feedback from the LLM, agents can refine their approach and rectify any mistakes made during problem-solving tasks. This iterative process leads to continuous improvement in their performance over time.
The collaboration between agents and LLMs opens up new possibilities for efficient and reliable problem-solving. Agents can leverage the vast knowledge stored within LLMs to access information quickly and accurately. They can fetch real-time data from various sources, analyze it, and provide relevant insights or answers to users' queries.
For example, imagine an agent assisting in customer support tasks. It can utilize its dynamic problem-solving abilities to understand customer inquiries, retrieve relevant information from databases or knowledge bases, and provide accurate responses promptly. This not only improves customer satisfaction but also reduces the burden on human support staff.
In summary, agents powered by LLMs represent a significant advancement in problem-solving capabilities. Their dynamic nature enables them to adapt to different scenarios while continuously improving their performance through feedback loops with LLMs. By collaborating with humans as partners rather than replacing them, these agents enhance our ability to solve problems efficiently and reliably.
6. The Importance of Data Labeling
Data labeling remains a cornerstone in AI, as every sophisticated AI model relies on meticulously curated and labeled data to learn and make accurate predictions.
Labeling data is assigning meaningful tags or annotations to raw data, such as images, text, or audio. These labels provide the necessary context and ground truth for training AI models. Without proper labeling, AI models would struggle to understand and interpret the data they are presented with.
Accurate and reliable data labeling is crucial for developing AI models that generalize well across different scenarios. It ensures that the models learn from high-quality labeled examples, enabling them to make accurate predictions on unseen or real-world data.
Data labeling also plays a vital role in addressing bias and fairness concerns in AI systems. By carefully curating diverse datasets and ensuring balanced representation, we can mitigate biases that may arise during model training. This helps create more inclusive and equitable AI solutions.
Moreover, data labeling allows us to capture domain-specific knowledge and nuances essential for specific applications. For instance, in medical diagnosis, accurately labeled medical images enable AI systems to identify abnormalities or assist doctors in making informed decisions. In natural language processing tasks like sentiment analysis, precise labeling helps train models to understand the subjective aspects of human language.
In summary, data labeling forms the foundation of successful AI development. It provides the necessary labeled examples for training models effectively while addressing bias concerns and capturing domain-specific knowledge. By investing in accurate and reliable data labeling practices, we pave the way for building robust and trustworthy AI systems.
7. Embracing the Future of Data Labeling
In embracing the future of data labeling, Adala's agents, powered by LLMs, offer dynamic and versatile solutions for efficient and reliable data labeling. Integrating LLMs into the labeling process enhances label quality while reducing the cognitive burden on human annotators. Combining human expertise with AI efficiencies is crucial as our reliance on AI models grows.
Human-in-the-loop curation ensures the efficiency, context-awareness, and reliability of AI systems. By involving human annotators in the labeling process, organizations can achieve the highest quality labels, especially for complex or nuanced tasks. Human judgment remains essential in achieving accurate and robust AI models.
Agents redefine problem-solving by collaborating with humans and continuously improving their abilities. They dynamically solve problems in unknown environments, fetching real-time data and providing reliable answers. This collaborative approach between humans and agents leverages the strengths of both parties to tackle challenges effectively.
Data labeling remains a crucial aspect of AI development. Every sophisticated AI model relies on meticulously curated and labeled data to learn and make accurate predictions. It is the foundation for building accurate and robust AI models to address various real-world scenarios.
In conclusion, embracing the future of data labeling involves harnessing the power of Adala's agents, enhancing label quality through LLMs, ensuring human-in-the-loop curation, redefining problem-solving with collaborative agents, and recognizing the importance of data labeling in developing accurate AI models.
Resources